
An open letter to my colleagues at Emory Law
Dear colleagues,
Generative AI has made every form of assessment other than a supervised exam (written or oral) essentially worthless as a measure of what a student knows. I will expand on that below, but it’s hard to see how it can seriously be a matter for debate any more. The obvious response is to bring exams back into the classroom. We should. Many of you have already. But we also need to think more carefully about whether those exams are an appropriate response to the current environment because generative AI is not the only development threatening the integrity of our assessments.
In-class exams don’t work the way they did in the 1990s when I was in law school. The standard long-fact-pattern exam, which asks students to spot and apply as many issues as possible under time pressure, has always rewarded speed in addition to understanding. Once upon a time, that might have been defensible, but it now interacts perversely with an accommodations system under which a third of a class may have extra time.
The good news is that some small changes can address both the challenges of generative AI and our current accommodations environment. Supervised, closed-book exams with a word limit that actually constrains would ensure that we are assessing students on their understanding of the law, not ChatGPT’s or Claudes. This format also makes sure that exams reward understanding more than typing speed and that extra-time accommodations do what they are meant to do instead of the opposite: create a more level playing field, regardless of disability, rather than creating an uneven playing field and perverse incentives.
We have it within our power to respond to generative AI in a way that also makes our exams fairer and more meaningful. We should all make the necessary changes now.
Take-home exams are dead
I don’t have any easy answers for what to do with legal writing, seminars, or experiential courses, but for ordinary doctrinal courses, take-home exams are dead. Some of you may resist this conclusion because you once fed a torts or contracts exam to ChatGPT and received a mediocre answer.
But there are two things we all need to understand as to why that is no longer any kind of answer. First, 2023 was a long time ago in AI terms. In January 2023, ChatGPT earned a C+ average on four real Minnesota law finals. Two months later, GPT-4 passed a complete Uniform Bar Exam, scoring above every state’s cut score. (OpenAI’s “90th percentile” claim was inflated; the pass was not.) Law professors at Maryland have tested several iterations of GPT on their own finals and found grades steadily improving to the point where OpenAI’s o3 earned three A+s, one A, one A-, two B+s, and a B across eight exams. Their 2026 follow-up found performance had plateaued at A-range.
Second, all those results come from very simple prompting. Our students are likely more resourceful. The enterprising ones are not typing “answer this question”; they are dissecting the casebook, the syllabus, and their notes, and feeding those to various models along with much more structured prompts. If you give me 24 hours, the course materials, and some time with Claude Code, I am certain I can ace any doctrinal law school exam while learning close to nothing. If I can, so can our students.
A natural experiment
If you want to see what happens when students use generative AI on their exams, consider Roberto Serrano, an economics professor at Brown, whose story Inside Higher Ed reported this month. This spring, after a December mass shooting at Brown left students anxious about classrooms, Serrano gave his Welfare Economics class a take-home midterm, the first in nearly two decades teaching the course. Enrollment nearly tripled, presumably because all of a sudden students developed a passion for Pareto optimality. The midterm average was 96 percent on a deliberately harder exam, against a historical range of 65 to 80. Forty of the 86 scored a perfect 100. Serrano ran the exam through ChatGPT, and the result mirrored several students’ answers. When he made the final in-person and proctored, eighteen students dropped the course, and a further nine stayed enrolled but skipped the exam. The final’s average was 48.6 percent, a historic low; nineteen students failed even after he lowered the passing line.
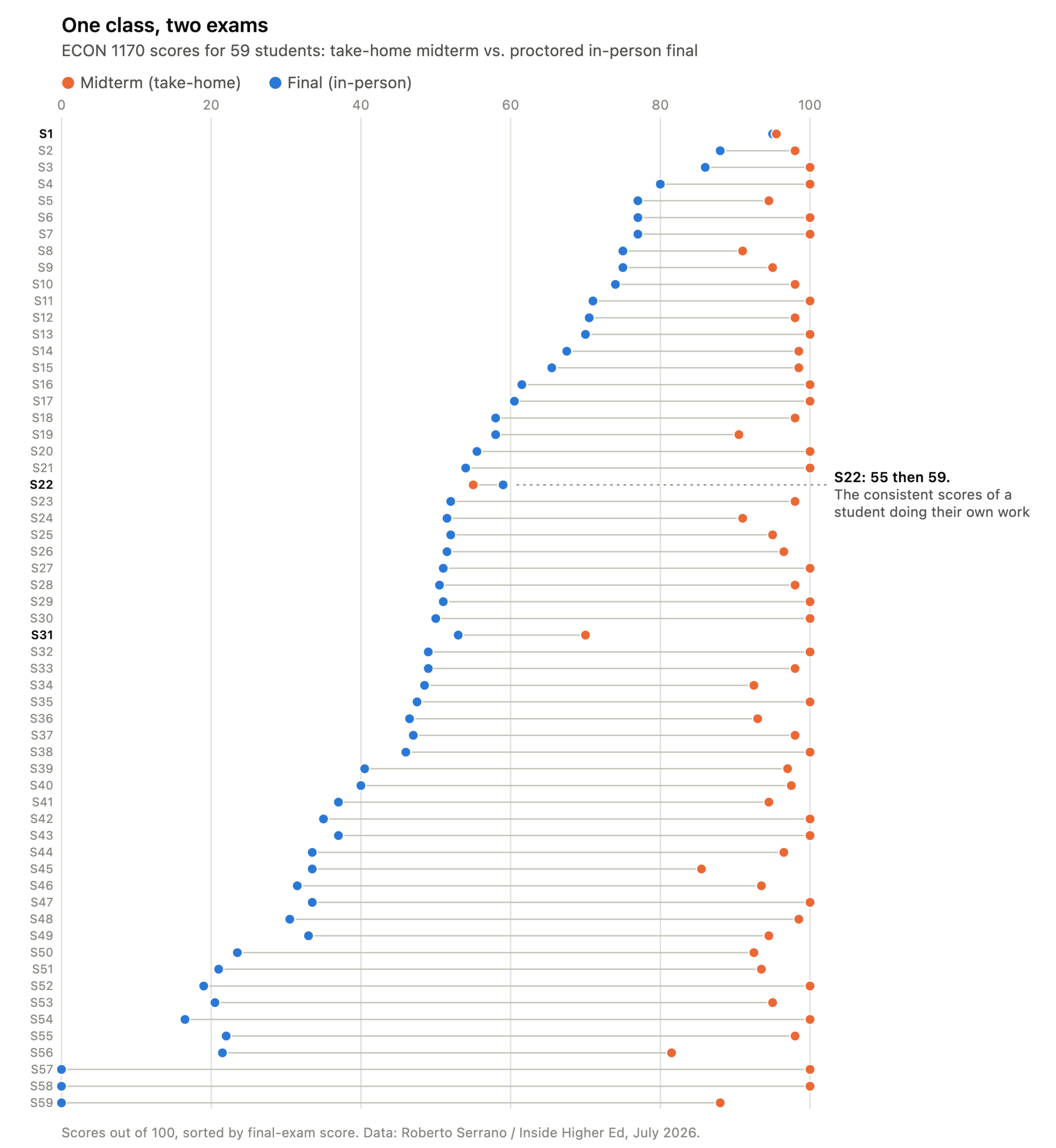
The chart shows the gap, student by student: for most of the class, the midterm sits near the top, and the final lands 30 to 50 points lower. Obviously, this is not one or two students having a bad day. Look carefully at the figure, and you will see three students who stand out, because their performance scores are moderately close together (S1, S22, and S31). S22 would have had the worst midterm score in the class if Serrano had not voided that assessment. The cost of AI-corrupted assessment falls hard on honest students like S22; whether that matters more than the lost learning these figures also suggest depends on how you balance these incommensurables.
Your take-home exam has close to zero validity as a measure of legal knowledge or skill.
False solutions
You might think that technology is coming to save you. AI detection tools can tell you something about a cohort, but as a means of identifying which individual student cheated, the tools are inherently unreliable. AI detection tools are nothing like plagiarism detection tools—they don’t compare new inputs to a database of prior works looking for a match; they cast auguries and scrutinize the shadow of a digital Punxsutawney Phil to diagnose AI drafting (not really, but they may as well). It is telling that OpenAI shut down its own detector after six months for “low rate of accuracy.” I would rather toss a coin than use an AI detector on a single piece of work (because in the former case I would not kid myself that I had learned anything), and I am not alone. A peer-reviewed evaluation of fourteen AI-text detectors found them “neither accurate nor reliable.”
The problem with the obvious solution
The obvious answer is to go back to a world of in-class exams using software to deactivate students’ access to the internet. “Electronic BlueBook,” “Softtest,” and other similar platforms have this functionality. We should all do this, but its not enough. We need to think harder about exam conditions.
Since time immemorial (or at least since The Paper Chase), law school exams have used time scarcity to produce variation in answer quality that we then map onto a grade distribution. To make sure they get a good distribution, law professors invariably pack their exams full of issues and sub-issues that are almost impossible to address in the time allotted. The theory was that students who understand more would do more with the time they had. That made sense in the blue-book era when everyone wrote at about the same speed and had the same time to complete their exams. Both predicates are false.
Typing speed varies, a lot
Most law schools moved from handwritten exams to exams typed on student laptops around twenty years ago or more. At the time, I don’t think anyone gave much thought to the fact that there is a lot more variation in typing speeds than in handwriting. Students average around 23 words per minute in handwriting, with the fastest writing twice as fast as the slowest. But according to a study at BYU a few years ago, typing speeds among law students ran from 21 to 108 words per minute: a 5x advantage rather than a 2x advantage.
It’s hard to imagine that anyone can defend the proposition that class rank should be determined by a typing test—except that revealed preference indicates that some of you do.
An arms race we built
Extra-time accommodations have become very, very common. In my Property class last semester, a third of the students had them, mostly time and a half, occasionally double time, and colleagues around the country report much the same.
Some of this reflects good news. It tracks a broader, more humane understanding of who struggles and why, and less stigma about saying so. I have no interest in relitigating any of that. I don’t want to demonize students seeking accommodations. I am dyslexic and have ADHD, and I remember how hard it was fighting to have my teachers and professors evaluate me on what I had written as opposed to my spelling. But I also know that if I had been given 50 percent more time than my fellow students in an open-book exam, that would have over-corrected.
A system that hands a large advantage to anyone with the right paperwork will not stay honest for long. Once students perceive that extra time confers a significant advantage in a highly competitive environment, the incentives are obvious. The legal standard for a disability is, by design, not a demanding one, so the rational move for a student under pressure is to find a name for whatever they are feeling and get in line. I have heard first-hand from students who feel this pressure and are wrestling with this dilemma. Many commentators see accommodations as a strategic tool for competitive advantage, with growth concentrated at the most selective and expensive institutions, but it’s important to understand that strategic is not the same as dishonest. No dishonesty is required, given the prevalence of ADHD, anxiety, etc.
Extra-time accommodation started out as a remedy for unfairness, but usually not a terribly well-thought-through one. Of course, I have no idea in any individual case whether a student should be accommodated with extra time, and if so, how much. I also suspect, based on my conversations with the university department that determines these accommodations, that they don’t either. When I pushed for an explanation from DAS last year, I was told that each evaluation was an “individualized assessment.” When I and another professor asked, “on what criteria?” we were offered the phrase “individualized assessment” as though it answered that question. It doesn’t.
We cycled through the “what criteria?” – “individualized assessment” loop several times until it emerged that the primary determinants of how much extra time to award were a combination of (a) what the student had asked for, (b) what they had received at a prior institution, and (c) what the relevant medical professional/therapist had recommended.
Our disability offices do their best, but their focus is compliance with the law as it has been explained to them. As far as I know, they are neither teachers, psychologists, nor psychiatrists, and thus they are poorly positioned to second-guess accommodations recommended by mental health professionals, already agreed to by some undergraduate institution. They also seem to have trouble understanding how something as benign-sounding as time and a half interacts with a curved, time-pressured exam.
How extra time distorts the results
I don’t see the accommodations landscape changing in a hurry, but we could do a far better job designing assessment so that extra-time accommodations are more equalizing than distortionary.
The premise of extra time is that it helps only those who need it. That premise has been tested repeatedly and does not appear to hold up. It is utterly unsurprising that extended time tends to improve the performance of all students, but how much obviously, it depends on exam conditions.
The unfairness of extra time is at its worst in open-book, points-accumulation exams (i.e., exams where you get points for saying something correct that matches the rubric, with no deduction for irrelevant or even incorrect observations). Not long ago I sat down with a student unhappy with his grade in one of my courses. He said he struggled with my 1,500-word limit on the three-hour exam, which contained one essay and a battery of multiple-choice questions. I asked, offhandedly, how much he would have written without a word limit. Six thousand words, he said.
Six
Thousand
Words
This student had an accommodation for double time in exams, and his strategy was: “you just dump your outline to make sure you hit every issue.” I don’t doubt that the condition behind his accommodation was genuine. But we are failing students like this, failing students who don’t have accommodations and failing the legal profession. Exams that are a race to accumulate correct statements, with no penalty for wrong ones and twice as much time for some as for others can’t be a valid measure of achievement at law school or legal ability. In my experience, clients want clarity and synthesis, the exact opposite of the “dump your outline” mentality.
My sympathies are entirely with people who struggle to read and write in conventional ways. But accommodations should be calibrated and focused on removing artificial impediments to performance that don’t reflect real-world conditions. We shouldn’t just be haphazardly giving some students who are stressed, depressed, or have learning difficulties an advantage over others (many of whom are probably also stressed, depressed, or struggling with learning difficulties).
When our unaccommodated students take their exams, they look around the room at the empty seats and do the math. Of course, every cohort contains students whose accommodations are unambiguously warranted. But poorly designed exams manufacture both unfairness and, just as corrosive, the perception of unfairness, among students who can count as well as I can.
I don’t have a perfect solution, but we can do a lot better.
The fix: supervised, closed-book exams with constraining word limits
All doctrinal courses should be assessed by supervised, closed-book exams with constraining word limits.
That regimen will not fix admissions or the accommodations pipeline. But it will dilute the incentives for an accommodations arms race and make our grades a fairer reflection of relative ability. When extra time no longer buys a materially better grade, far fewer students have any reason to chase a diagnosis, and those who genuinely need the accommodation get it without the side-eye.
Word limits
Word limits that actually constrain are vital.
You should set your word limit so the exam is not a typing test. This means setting it well below what students can physically produce (1,500 words, say, where the average student could type 2,500–3,000 in three hours). If you think it takes 3,000 words to write an A answer in your exam, you should give all your students six hours. If that sounds as awful to you as it does to me, write a simpler exam and give them 1,500 words. The worst way to set a word limit is to imagine what a fast typist would write in the standard time allowed in the course of a perfect answer. That will result in a limit that is basically no limit at all.
Word limits force students to prioritize among issues, which is a more important skill than typing fast. It’s a skill lawyers practice most days. With proper word limits, the equalizing effect that extra time is meant to have is preserved, but the unfair advantage is substantially reduced. Not eliminated, because nothing is perfect, but substantially reduced. Proper word limits would also mean that students who type slower than average have very little need or incentive to seek accommodations in the first place.
Closed-book
Closed-book exams reward internalized knowledge. You may feel they unfairly privilege memorization over some idealized form of “true, knowledge-free understanding,” but recall and understanding actually tend to go hand in hand.
More importantly, open-book exams pour gasoline on the unfairness of extra-time allocations. How can you make a fair comparison between one student with two hours and barely enough time to look at their outline, and another student with four hours and the luxury to consult an outline they may not have even written? If you really think it is unfair to test students on their ability to remember the elements of adverse possession and the like, you can include that information in the exam.
Supervised
All our exams should be properly supervised to ensure that what is meant to be a closed-book exam is really a closed-book exam. Accommodations that allow students to take their exams in private rooms are incredibly resource-demanding and undermine the integrity of the exam process if that leads to students taking exams unsupervised. Students have reported to me that other students have bragged about using AI in unsupervised rooms. Whether this hearsay is true or not, if students believe it is true, we have a serious problem.
What to do about it
This letter is written for my fellow law professors, and the message is simple. Generative AI and the shifting accommodation landscape both demand a response. There are things that should be done at the institutional level, and I hope we do them. But the most immediate remedy is already in front of us, and it is entirely within our power.
You do not need a committee or a faculty vote. You can change your syllabus now, for the courses you will teach next semester.
I have made this an open letter because every law school around the country seems to be facing this exact same problem. We, as a faculty, have been having versions of this conversation for quite some time, but it is also something very much on the minds of our students.
Sincerely,
Matthew Sag
Jonas Robitscher Professor of Law in Artificial Intelligence, Machine Learning, and Data Science, Emory University

